目录
最近智能体Ai agent的垂直领域的技术非常地火,所以这篇文章是介绍目前最火的三种技术,MCP、Skills(技能)、CLI (命令行)。特别是最近比较火把前任、领导、同事蒸馏成skill。所以自然思考背后的原理。

MCP
 Anthropic 于2024 年11 月提出了"模型上下文协议"(MCP)的概念。 它最初是一个开源项目,旨在改进语言模型与工具和数据的交互方式。 从那时起,MCP 获得了广泛关注。
Anthropic 于2024 年11 月提出了"模型上下文协议"(MCP)的概念。 它最初是一个开源项目,旨在改进语言模型与工具和数据的交互方式。 从那时起,MCP 获得了广泛关注。
工作原理
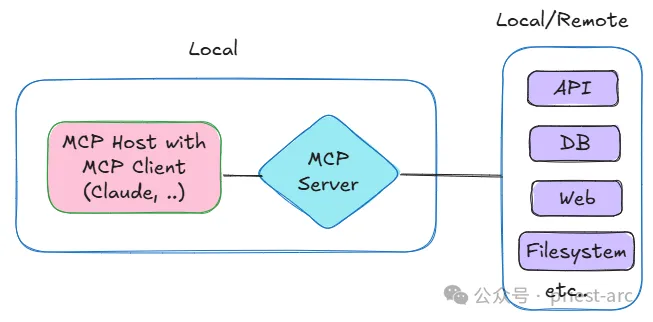
MCP 核心是让我们能方便地调用多个工具,那随之而来的问题是 LLM(模型)是在什么时候确定使用哪些工具的呢? Anthropic 为我们提供了详细的解释,当用户提出一个问题时:
- 客户端(Claude Desktop / Cursor)将问题发送给 LLM。
- LLM 分析可用的工具,并决定使用哪一个(或多个)。
- 客户端通过 MCP Server 执行所选的工具。
- 工具的执行结果被送回给 LLM。
- LLM 结合执行结果,归纳总结后生成自然语言展示给用户!
更细致的工作流程如下:用户输入要完成的任务或问题
- 第一步:Host根据用户输入,确定要调用哪个Client;
- 第二步:Client将用户输入和 一些环境变量 ,传递给Server;
- 第三步:Server根据Client传递的内容进行任务处理,并将结果反馈给Client;
- 第四步:Client将结果传递给Host;
- 第五步(可选):如果有需要,继续重复2到4,调用不同的mcp完成不同的任务;
- 第六步:Host将重新组装Prompt,传递给大模型;
- 第七步:大模型完成任务之后,将结果反馈给Host;
- 第八步:Host将结果展现给用户。
MCP协议的核心组件
MCP协议定义了三大核心能力,这些能力共同构成了AI智能体与外部世界交互的完整方案。
资源(Resources)
资源是AI可以读取的外部数据,如文件、数据库、API响应等。每个资源都有唯一的URI标识。
服务端示例(Python + FastMCP):
from mcp.server import FastMCP from mcp.types import Resource, TextResourceContents # 创建MCP服务器 mcp = FastMCP("my-file-server") @mcp.list_resources() async def list_resources() -> list[Resource]: """列出所有可用资源""" return [ Resource( uri="file:///workspace/README.md", name="readme", description="项目README文件", mimeType="text/markdown" ), Resource( uri="file:///workspace/config.json", name="config", description="应用配置文件", mimeType="application/json" ), Resource( uri="file:///workspace/src/", name="source-code", description="源代码目录", mimeType="text/plain" ) ] @mcp.read_resource() async def read_resource(uri: str) -> str | bytes: """读取指定资源""" import os path = uri.replace("file://", "") if os.path.isdir(path): # 返回目录列表 files = os.listdir(path) return "\n".join(files) with open(path, "r", encoding="utf-8") as f: return f.read() if __name__ == "__main__": mcp.run(transport="stdio")
工具(Tools)
工具是MCP最重要的能力,允许AI调用外部函数执行操作。 服务端示例(TypeScript):
import { Server } from "@modelcontextprotocol/sdk/server/index.js"; import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js"; import { CallToolRequestSchema, ListToolsRequestSchema } from "@modelcontextprotocol/sdk/types.js"; const server = new Server( { name: "github-mcp-server", version: "1.0.0" }, { capabilities: { tools: {} } } ); server.setRequestHandler(ListToolsRequestSchema, async () => { return { tools: [ { name: "github_get_issues", description: "获取GitHub仓库的Issue列表", inputSchema: { type: "object", properties: { owner: { type: "string", description: "仓库所有者" }, repo: { type: "string", description: "仓库名称" }, state: { type: "string", enum: ["open", "closed", "all"], default: "open" } }, required: ["owner", "repo"] } } ] }; }); server.setRequestHandler(CallToolRequestSchema, async (request) => { const { name, arguments: args } = request.params; if (name === "github_get_issues") { const url = new URL(`https://api.github.com/repos/${args.owner}/${args.repo}/issues`); if (args.state) { url.searchParams.append("state", args.state); } const response = await fetch(url.toString(), { headers: { "Authorization": `Bearer ${process.env.GITHUB_TOKEN || ""}`, "Accept": "application/vnd.github.v3+json", "User-Agent": "github-mcp-server" } }); if (!response.ok) { throw new Error(`GitHub API error: ${response.status} ${response.statusText}`); } const data = await response.json(); return { content: [ { type: "text", text: JSON.stringify(data, null, 2) } ] }; } throw new Error(`Unknown tool: ${name}`); }); async function main() { const transport = new StdioServerTransport(); await server.connect(transport); } main().catch(console.error);
Elicitation机制
允许AI在关键决策时请求人类确认:
{ "method": "tools/list", "params": { "elicitation": { "message": "此操作将删除生产环境数据库,确定要继续吗?", "acceptOptions": [ "确认删除", "取消操作" ], "context": { "resource": "production-db", "action": "delete" } } } }
版本协商策略
{ "protocolVersion": "2025-06-18", "supports": ["sampling", "roots", "elicitation"], "features": { "tools": { "dynamicRegistration": true }, "resources": { "subscription": true } } }
skill
中台思想
中台一词,常常出现在各种软件架构的设计中,其核心理念用两个字就可以概括:复用,即把相同功能抽离出来,减少重复建设,如下图:
 好,如果架构可以这样玩,为什么Prompt不行?我们做一个大胆的抽象:软件开发的整个过程等于所有Prompt的总和,那么请诸位回想一下,在你的VibeCoding中,有没有属于你的高频口头蝉?我想答案是:Yes。
好,如果架构可以这样玩,为什么Prompt不行?我们做一个大胆的抽象:软件开发的整个过程等于所有Prompt的总和,那么请诸位回想一下,在你的VibeCoding中,有没有属于你的高频口头蝉?我想答案是:Yes。
 好,既然有,为什么要每次都打字!这也太慢了,细细想想,目前AI的产出的速度好像完全受限于我们打字的速度(PS:有的时候在工位就想用语音和AI沟通)所以能不能优化这个流程,学习中台理念,把你的“口头蝉”提前封装好,用的时候,直接一个快捷键!好,到这里我们就可以回答一个问题:什么是Skills?答:公共的Prompt就是Skills!
好,既然有,为什么要每次都打字!这也太慢了,细细想想,目前AI的产出的速度好像完全受限于我们打字的速度(PS:有的时候在工位就想用语音和AI沟通)所以能不能优化这个流程,学习中台理念,把你的“口头蝉”提前封装好,用的时候,直接一个快捷键!好,到这里我们就可以回答一个问题:什么是Skills?答:公共的Prompt就是Skills!
 好,我们接着说,如果软件开发的过程就是Prompt的总和!那我们想想,其实软件开发的流程是非常固定的,从设计->开发->测试->运维,那我们就可以把SKIlls按流程进行分类!让它们归到这个框架内。这样我们就拥有了一个识别方法,即面对这成千上万个Skills,我们就可以分区,哦,它对于我们哪些工作环节是帮助的。通过这种方法,我们就可以把好的经验和方法覆盖到软件工程的整个全周期中,做到极致的提效!
好,我们接着说,如果软件开发的过程就是Prompt的总和!那我们想想,其实软件开发的流程是非常固定的,从设计->开发->测试->运维,那我们就可以把SKIlls按流程进行分类!让它们归到这个框架内。这样我们就拥有了一个识别方法,即面对这成千上万个Skills,我们就可以分区,哦,它对于我们哪些工作环节是帮助的。通过这种方法,我们就可以把好的经验和方法覆盖到软件工程的整个全周期中,做到极致的提效!

Skills设计哲学:恰好而非更多
但事情没有那么简单,随着“复用”的增多,当你给AI装上了一大堆的SKills,一个工程化的问题随之而来,我们知道AI在工作的时候,并不是一个无限的资源空间,而是运行在一个特定大小的桌子上(上下文窗口)。试想我们把所有东西都堆在桌面上,桌面就会很乱,结果就是AI开始胡言乱语,幻觉增多,因此,Skills的设计理念是: 具体如何做呢?也简单,搞个分级缓存,当输入Prompt的时候,不要带上全量的Skills信息,而是最基本的元信息,AI会按照语意进行匹配,匹配到了才会加载实际的内容,这就是渐进式加载,官方叫:渐进式披露,如下图所示:

为什么经验可以沉淀了?
另外一个有趣的问题:为什么说经验能够复用了,而在过去几十年里却做不到呢?我想是因为:AI时代,人类的语言已经成为了一门全新的“编程语言”,所以只要能够被以文字形式沉淀的知识都会被AI理解,这是一件细思极恐的事,这意味着:任何以文字承载的领域,AI终将成为大师,超越大多数人类,最后它会成为最懂编程、最懂历史、最懂..的存在。 经验可以沉淀,这不仅对个人,对团队来说,作用也巨大,它实现了“经验”的低成本共享,个人经验将会以Skills的形式快速的在团队内传播,团队的整体战斗力也随之迈上了一个新的台阶。
 最激动的是:当Skills的数量达到一定规模时,其实我们就相当搭建了一个专门给AI用的技能商店,当AI遇到新的复杂问题时,它可以自动匹配Skills库,让复杂的问题通过基础Skills的组合得到解决。
最激动的是:当Skills的数量达到一定规模时,其实我们就相当搭建了一个专门给AI用的技能商店,当AI遇到新的复杂问题时,它可以自动匹配Skills库,让复杂的问题通过基础Skills的组合得到解决。
 另一方面,Skills的成功,给我们了一个很好的启发:AI时代,系统设计将从面向于人设计转向面向AI设计。一份数据,我们需要有给人好理解的版本,也需要有给AI好理解的版本!
另一方面,Skills的成功,给我们了一个很好的启发:AI时代,系统设计将从面向于人设计转向面向AI设计。一份数据,我们需要有给人好理解的版本,也需要有给AI好理解的版本!

如何开发Skills:从归纳法到演绎法
那对于个人开发者,我们该如何打造属于自己的 Skills?要回答这个问题,我们不妨先回忆下上学时是如何解数学题的。绝大多数数学题,都是以既定公理为起点,通过严谨的逻辑推导得出答案。这种解题思路,正是典型的演绎法。这也折射出中国传统教育的核心特点:更侧重演绎法的应用,而忽视了对于归纳法的培养。但在真实的工作中,情况却截然相反,我们的 “经验”,本质上是一种 “人肉强化学习” 大脑在日复一日的实践中不断试错、迭代,将零散的实践感悟进行提炼,最终在潜移默化里,下意识形成了可复用的 “经验”,而这一过程,多数是归纳法的功劳。我们举个例子体会下:
有一天我睡前吃了100元的麦当劳,虽然当时很满足,但第二天起来却倍感不适。但是由于太好吃了,我还是连续三天睡前吃了夜宵,结果每天都出现了同样的不适。由此,我归纳出一个定律:吃夜宵会导致第二天早上身体不适。 后来,我爱吃夜宵的同事小明,早上起来也感觉常常不适。我便将“睡前不吃定理”分享给了他,他实践一周后,不适感果然明显改善这就是既定的规律再应用到特定场景、解决实际问题的过程,就是演绎法。 而我们要开发属于自己的Skills,也是这个路子:重复以上两个过程,我们需要先将工作中的案例总结提炼(归纳),固化为Skills,用以应对同类问题(演绎),或是再次反馈完善这个Skills,这便是Skills开发的核心思路!

真正的难点,需要:向外洞察+向内觉察
但到这,还没有完,因为难点并不是:如何用归纳法和演绎法,为什么?因为创造一个Skill的难点,从来不在方法,而在于:你是否有能量去洞察问题。
Skill的本质是一种解决方案,它与问题本就是一体两面,若问题不存在,那Skills再强大也毫无意义。因此,要创造出一个有价值的Skill,前提是拥有敏锐的洞察力,这便 “向外洞察”:我们需要从日常工作中,精准地捕捉那些反复出现的问题,再从解决问题的过程中,总结出经验。我曾听过一句话:“如果你看见了,就请仔细观察”,在这个AI飞速发展的时代,解决问题的能力会被AI逐步取代,但精准发现一个有价值的问题,恰恰是最难被替代的核心能力,也是Skill的价值根源。
除了向外洞察,“向内觉察”同样不可或缺。回想下,大多数我们遇到的问题,早已有了成熟的解决方案,真正的新问题少之又少,只是我们常常对此“不自知”,我们习惯了下意识地解决问题,却从未认真复盘过自己的思考与操作过程。在这个时代,我们需要像禅修般向内观:面对具体问题时,自己是如何一步步分析、拆解、解决的?把这个隐性的、下意识的过程梳理清晰,再沉淀成AI能够理解的领域知识,正是开发Skill的核心要点。
举个例子,比如当你遇到Bug时,你是如何排查的?好好回想这个完整过程,把每一步操作、每一个判断逻辑梳理清楚,让AI照着这个逻辑去执行,这一点,我会在后续的实践分享中详细展开。除了自己的去总结,其实也可以利用AI工具,当你用AI解决完一个新问题的时候,别急着关闭对话框,让Agent自己观察你的Prompt过程,让他自己总结沉淀,这个过程只需要你在解决完问题后,加一句prompt即可。

建模一词源于建筑学,盖房子的核心逻辑是先设计图纸,再依据图纸施工。但软件开发的场景有所不同:由于需要持续迭代功能、不断完善产品,就像要不停“盖房子”,这就导致设计图始终处于动态变化中。实际情况往往是,面对一个新需求,我们不清楚原来的“图纸”是什么样子。因此,面对一个新需求,还原这份“图纸”是革命的首要任务,而通过现有工程代码反推出“图纸”的过程,就是逆向建模。
那模型里有什么呢?我们可以总结为三个部分:实体、规则和行为。剩下的工作,不管是要去理解需求或是开发需求,我们本质上都是围绕着以下三个问题展开:
- 实体关系是什么?有什么变更?
- 流程是什么?有什么变更?
- 行为是什么?有什么变更?

当我们回答好了这三个问题,我们的代码也就写的差不多了,这种方法让VibeCoding更加精细化,让Vibecoing建立在图纸之上,而非抽象的语言之上。那我们具体要如何表达呢?我们详细讨论下。
1、 实体的显化表达,这里尝尝用的就是传统的UML建模,我们通过类对象及其关系去还原结构,通过不同的颜色来表示需求的改动!

本文作者:曹永皓
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!